探索ChatWeb3,这是一个利用ChatGPT进行区块链数据分析的聊天机器人。在OpenAI的GPT,Langchain和Flipsidecrypto的支持下,我们研究了其在AI驱动的区块链分析方面的工作流程,示例,挑战和未来潜力。
介绍
区块链技术的快速发展创造了对可访问的、用户友好的数据分析工具的迫切需求。人工智能(AI),特别是像ChatGPT这样的大型语言模型(LLM),为满足这一需求提供了巨大的潜力。然而,利用人工智能进行区块链和加密货币数据分析既有优势,也有挑战。
就在本周,币安宣布为其学院推出一款由ChatGPT驱动的聊天机器人Sensei。这个聊天机器人经过了该学院1000多篇文章的培训,旨在提供教育指导,而不是实时区块链数据。例如,当被问及有关特定代币交易量的问题时,聊天机器人可能会推荐与“交易量”或“交易量加权平均价格(VWAP)”相关的文章。
在并行开发中,Solana Labs最近发布了一个ChatGPT插件,使用户能够通过AI驱动的聊天机器人访问实时区块链数据。根据Twitter上分享的屏幕截图,该插件可以执行诸如检索特定地址拥有的NFT信息等任务。该插件利用了来自超空间的 API,这是一个基于 Solana 的综合 NFT 平台。
一个更通用的 ChatGPT 驱动的区块链数据访问工具可能会利用广泛的数据库,托管跨多个链的各种类型的区块链数据。目前,区块链分析师通常使用SQL来查询由Dune和Flipsidecrypto等提供商策划的数据。由于ChatGPT可以将自然语言提示转换为SQL,因此创建一个允许用户通过ChatGPT直接与这些SQL数据库交互的工具可以使区块链数据访问民主化。通过消除对专业编程技能(如SQL)的需求,该工具将使更广泛的受众能够进行区块链数据分析。
我们离实现这一愿景还有多远?为了探索可能性和挑战,inWeb3 一直在开发 ChatWeb3 – 一种人们可以用来访问加密和 Web3 数据的聊天机器人。在以下部分中,我们将分享从这项工作中收集的初步结果和见解。
聊天网3原型实现
本节介绍 ChatWeb3 原型的关键组件,讨论 AI、加密和区块链元素、集成过程和前端用户界面。
.AI: 对于AI组件,我们的ChatWeb3原型采用了OpenAI的gpt-3.5-turbo大型语言模型(LLM)。该模型在功能和成本之间提供了良好的平衡,因为它的价格比较新的 GPT-1 型号便宜得多,价格不到 10 的 4,使其成为测试目的的合适选择。
加密/区块链: 在加密和区块链方面,ChatWeb3目前由Flipsidecrypto提供支持。它包含来自众多链的大量精选和注释区块链数据,托管在 Snowflake 数据仓库中。
集成: 我们利用Langchain开发框架来集成AI和加密组件。具体来说,我们利用了Langchain的SQL工具包概念和ChatAgent。为了确保与Snowflake上Flipsidecrypto数据库的数据库和模式结构兼容,我们对代码和提示进行了必要的自定义。
前端:前端具有托管在Gradio上的简单聊天界面,该界面在回答问题时显示聊天历史记录和AI的思维过程。鉴于像GPT这样的LLM可以为用户查询生成不同的解决方案(正确和不正确),因此在实验期间检查中间过程(尤其是实际的SQL代码)以验证输出至关重要。
ChatWeb3 中的查询流如何工作?
以下部分介绍 ChatWeb3 中的查询流,详细介绍不同实体(包括 ChatWeb3 代理、GPT 和数据库)之间的通信过程。该系统旨在促进用户、人工智能和区块链数据之间的无缝交互。
考虑一个向 ChatWeb3 提交问题的用户,以下是接下来发生的事情的列表。
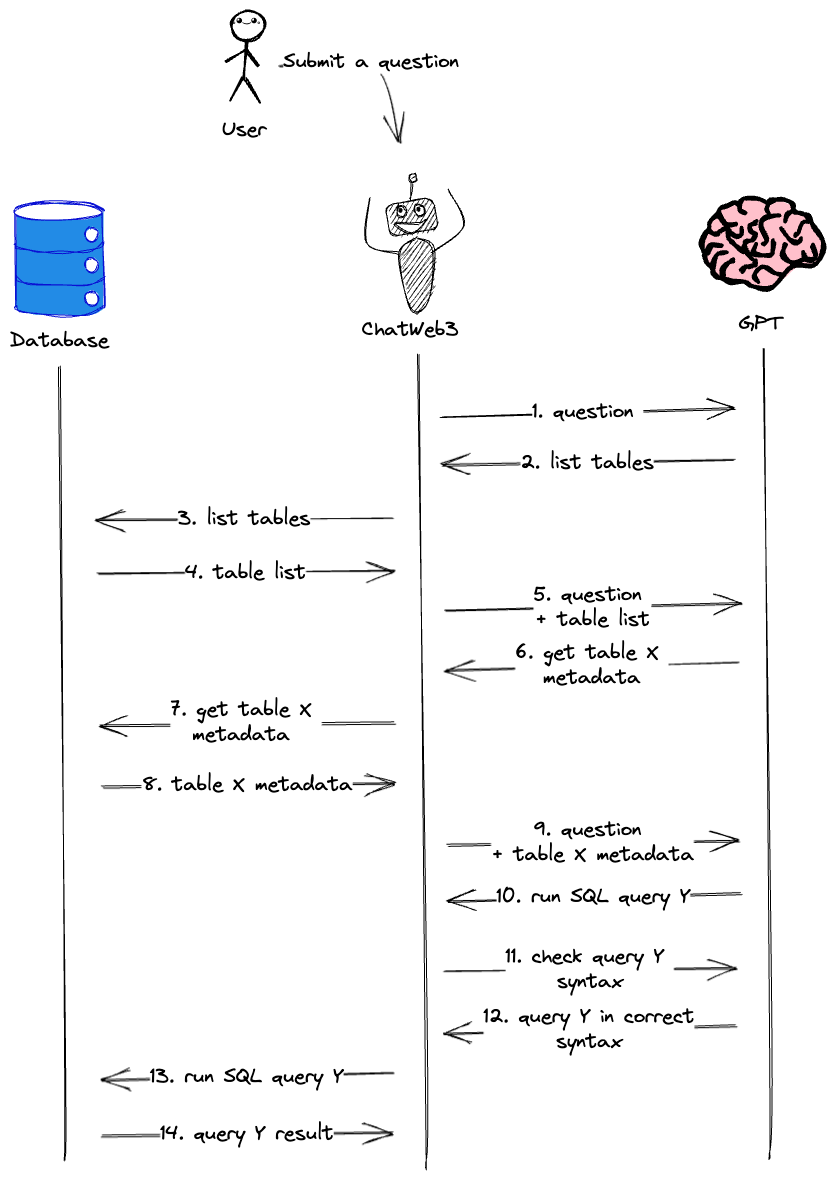
- ChatWeb3 代理会收到用户的问题并将其提交给 GPT 以获取进一步说明。
- GPT 通过请求代理查询数据库中的可用表来响应。
- 代理运行数据库查询以检索表信息。
- 数据库将表信息返回给代理。
- 代理将表信息连同原始用户问题一起提交给 GPT。
- GPT 会检查可用的表格信息,并选择与用户问题最相关的表格。然后,它要求代理检查该特定表的元数据。
- 代理从数据库请求指定表的元数据。
- 数据库将表元数据返回到代理。
- 代理将表元数据以及之前的所有通信提交到 GPT。
- GPT 为原始问题构造语法正确的 SQL 查询,并指示代理针对数据库执行该查询。
- 在运行查询之前,代理会使用 GPT 仔细检查 SQL 语法的准确性(仅提供候选 SQL 查询)。
- GPT 确认 SQL 查询在语法上正确或提供其更正后的版本。
- 代理收到确认的 SQL 查询后,将继续对数据库运行查询。
- 数据库将查询结果返回到代理。
获取结果后,代理可以立即向用户显示信息,也可以选择将原始结果提交给 GPT,以便格式化更具描述性的最终输出。如果在查询过程中出现错误,代理将重新检查 SQL 语法并重试更正的查询。
GPT 在 ChatWeb3 中的作用
SQL 工具包
让我们更深入地了解 GPT 在 ChatWeb3 中的作用。Langchain SQL 工具包为 GPT 配备了四个特定的工具,这些工具通过其提示服务于不同的目的。这些工具包括:
- list_table_tool:列出所有可用的表。
- get_table_info_tool:检索给定表的元数据,例如列和示例行信息。
- query_database_tool:向数据库提交SQL查询并获取结果。
- check_sql_syntax_tool:检查 SQL 语句的语法正确性。
前三个工具与数据库系统交互以检索信息,而第四个工具是对 GPT 的单独调用,仅用于检查 SQL 语法,而无需访问数据库。
在我们的例子中,具体的工具如下(根据Langchain的默认工具定制):
- check_available_tables_summary:
输入为空字符串。
输出是可用表的全名列表 (database.schema.table),并附有其摘要说明,以帮助您了解每个表的内容。- check_table_metadata_details:
输入是在其全名 (database.schema.table) 中指定的一个或多个表名,并由逗号分隔。
输出是详细的元数据,包括这些表的列细节,以便您可以对它们构造 SQL 查询。- check_snowflake_query_syntax:
输入是雪花 SQL 查询。
输出是查询的语法检查结果。- query_snowflake_database:
此工具的输入包含语法正确的雪花 SQL 查询。它应该是 JSON 格式,只有一个具有查询字符串值的键“查询”。
输出是来自数据库的查询结果。
GPT 的主要作用是确定要采取的下一步操作(即,接下来应使用上述四个工具中的哪一个)以及如何执行该操作(即生成执行所选工具所需的适当输入)。
检查和选择表
当提出问题时,首先指示 GPT 始终从选择检查数据库中所有可用表的list_table_tool开始。众所周知,像ChatGPT这样的今天LLM容易产生幻觉。如果没有这个规范,GPT 模型会很乐意“发明”一些不存在的表和列来形成无效的 SQL 查询。在此步骤中,工具的输入为空,这将指示代理检索所有可用表。收到表列表后,GPT 需要决定查询哪个表。这是实际提示:
您必须始终从check_available_tables_summary工具开始检查数据库中的可用表,并选择一个或多个要使用的表(如果适用)。
这一步需要做出重要的权衡。默认选项是向 GPT 提供数据库中所有表的名称。在许多情况下,纯粹的表名没有足够的信息,并可能导致表选择不当。由于Flipsidecypto的大多数表格都带有注释列,因此我们用从表注释中提取的简要描述来增强表名称。我们已经看到,当启用大量表时,包含表描述提高了表选择的性能。
但是,添加说明会影响我们放入 GPT 提示窗口中的单词数,或者更准确地说,会影响我们放入 GPT 提示窗口中的语言标记。OpenAI的经验法则是每个令牌大约4个英文字符。我们使用的“gpt-3.5-turbo”模型的最大代币大小为 4K。此限制包括问题输入部分和响应输出部分。当我们向表描述添加更多内容时,它会占用整个令牌窗口的更多空间。更糟糕的是,此内容会累积在提示窗口中。当我们经历多个步骤时,每个步骤的输入和输出都会在提示窗口中堆叠在一起,以便以后的 GPT 查询更好地了解整个思维过程。但这种做法也挤压了提示的大小。出于这个原因,我们在这里执行示例测试时只启用了 Flipsidecrypto 以太坊数据库中的少量代表性表,具体来说,这些表是“ethereum.core.ez_dex_swaps”、“ethereum.core.ez_current_balances”、“ethereum.core.ez_token_transfers”和“ethereum.core.dim_labels”。但即使有这个表格列表,当我们询问代币交易或余额信息时,我们仍然经常看到 GPT 在“ez_dex_swaps”、“ez_token_transfers”、“ez_current_balances”之间做出不同的选择。这些表通常包含相互关联的信息,这些选择可能会导致也可能不会导致错误的结果。
使用正确的语法创建对所选表的 SQL 查询
选择表后,GPT 需要制定正确的 SQL 查询并将其返回给聊天机器人,聊天机器人会将查询提交到数据库。为避免出现幻觉,系统会指示 GPT 在为表创建查询之前始终检查表的元数据,并显示以下提示:
如果需要为任何表构造任何 SQL 查询,则必须始终使用 check_table_metadata_details 工具来检查表的元数据详细信息,然后才能为该表创建查询。请注意,您可以同时检查多个表的元数据详细信息。
在我们的测试中,此提示在很大程度上阻止了 GPT 在不查看表信息的情况下组成列。但是,当事情变得更加复杂时,例如,当它决定创建包含两个表的语句时,它开始忘记它,只请求一个表,然后组成另一个表或列。我们当然可以进一步修改提示以解决这些问题。但需要注意的是,要涵盖所有情况并不容易,更长的提示再次挤压了有限的整体提示窗口的空间。join
当我们选择要包含的表元数据以及如何在节省空间的同时呈现它们时,提示大小也是这里的一个考虑因素。我们通过包括来自 Flipsidecrypto 数据库的列注释以及列类型和每列的三个示例值来自定义此信息。
仔细检查 SQL 查询的有效性
当 GPT 生成 SQL 查询并将其返回给代理执行时,通常的做法是执行另一个 GPT 查询来仔细检查查询语法。在我们的例子中,我们发现这可能并不总是必要的,并决定不在提示中强调它,原因如下:
- 跳过此步骤可减少消息交换的往返行程,从而节省提示空间。
- 我们注意到check_SQL_syntax_tool将查询报告为有效但查询失败的情况。这通常是因为 GPT 使用发明的表或列生成语法正确的 SQL 语句。由于check_SQL_syntax_tool没有有关数据库中实际表和列的信息,因此无法准确验证查询的有效性。
因此,我们还调整了错误处理提示,以包括错误不是由纯语法问题引起的情况。这部分提示如下:
如果您从该工具收到错误query_snowflake_database则必须始终分析错误消息并确定如何解决它。如果是常规语法错误,则必须使用 check_snowflake_query_syntax 工具仔细检查查询,然后才能通过query_snowflake_database工具再次运行查询。如果这是由于表或列名称无效,则必须仔细检查check_table_metadata_details工具并相应地重新构造查询。
但是,使用当前设置和整体提示大小,通常没有足够的空间进行额外的交互轮次,以防出现错误。提示的表重新选择部分将需要在将来的版本中进行测试。
使用 ChatWeb3 探索一个简单的问答示例
让我们来看看使用 ChatWeb3 的简单问答示例:
What is the total daily trading volume in USD on Uniswap in the last 7 days?
以下是输出:

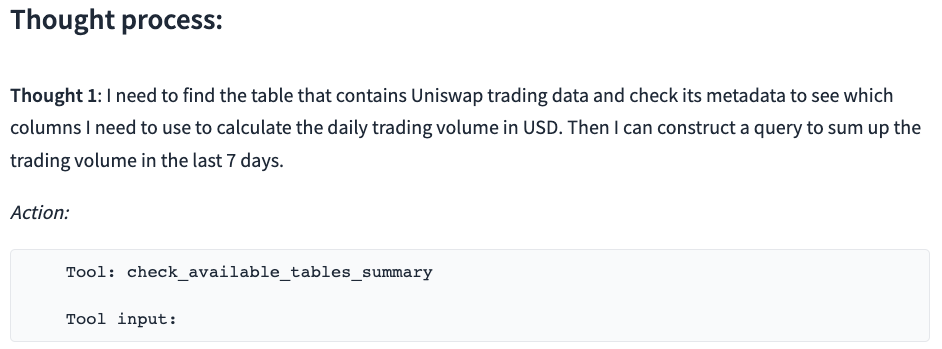
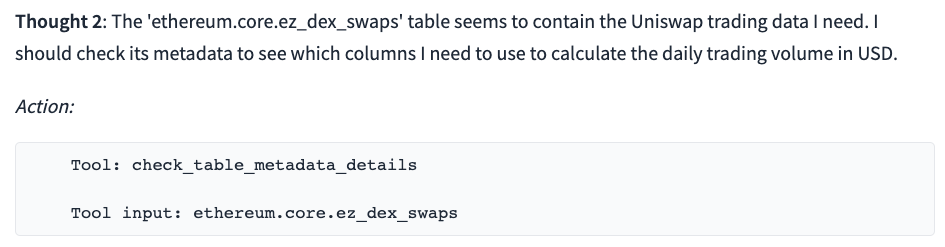
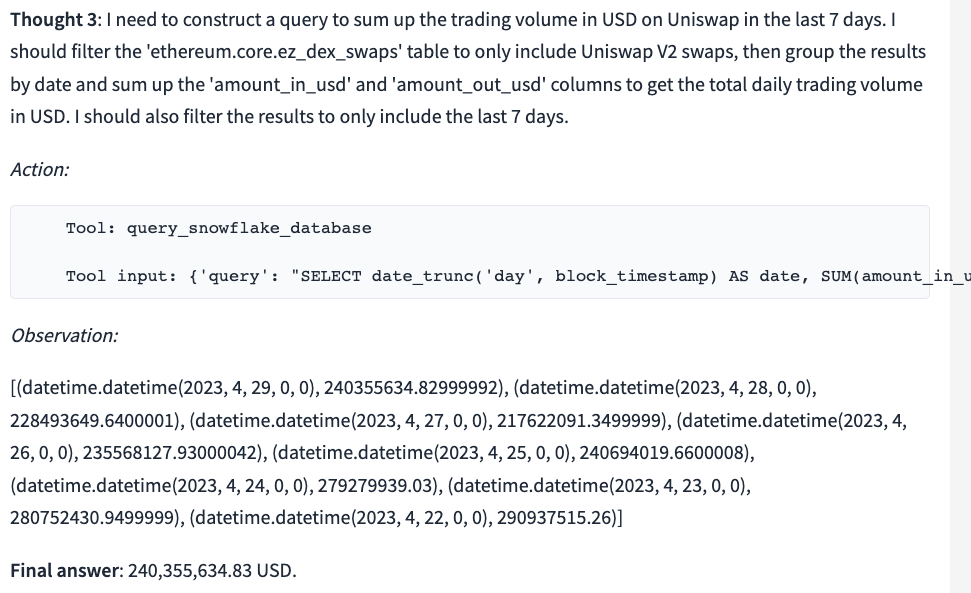
ChatWeb3 输出演示 GPT 首先请求表列表,然后从列表中正确选择ez_dex_swaps表。它还构造语法正确且有意义的 SQL 查询。
SELECT date_trunc('day', block_timestamp) AS date,
SUM(amount_in_usd) + SUM(amount_out_usd) AS total_volume_usd
FROM ethereum.core.ez_dex_swaps
WHERE platform = 'uniswap-v2'
AND date_trunc('day', block_timestamp) >= DATEADD(day, -7, CURRENT_DATE())
GROUP BY date ORDER BY date DESC但是,使用计算每日交易量可以被视为重复计算,因为这两个金额都代表掉期中涉及的代币,使用代币价格转换为美元。这是我们实验中经常出现的一个微妙问题,GPT 对语言输入的解释可能会偏离最初的预期含义。SUM(amount_in_usd + amount_out_usd)
此示例强调了验证底层 SQL 语句的重要性,这可能会破坏此方法的价值主张,因为用户仍然需要了解 SQL。在某些情况下,GPT 会为看似简单但模棱两可的提示构建复杂的查询,要求用户对 SQL 有扎实的了解来判断响应的有效性。因此,在这个阶段,GPT 更多地充当副驾驶或助手,而不是完全自主的工具。这可能也适用于许多其他AI用例。
要解决此问题,我们可以通过添加到问题中来使提示更明确:(only count one side of the trading amount)

现在,我们可以验证底层 SQL 是否仅按预期计数。amount_in_usd
SELECT date_trunc('day', block_timestamp) AS date,
SUM(amount_in_usd) AS total_volume
FROM ethereum.core.ez_dex_swaps
WHERE platform = 'uniswap-v2'
AND date >= DATEADD(day, -7, CURRENT_DATE())
GROUP BY date ORDER BY date DESC
此示例还演示了提示工程的重要性,该过程用于通过提供适当的提示并实现预期结果来改进 GPT 的推理,尽管其局限性。
更详细的案例研究
作者注:虽然本节受益于基本的SQL知识,但即使您浏览了特定的SQL语句,您仍然可以掌握主要思想。
现在我们已经对 ChatWeb3 的功能有了更深入的了解,让我们探索一个更现实、更有趣的例子来评估它是否可以帮助我们进行区块链数据分析工作。
模因币是一种加密货币,通过与互联网模因的关联而广受欢迎。他们的市场情绪通常由这些模因驱动,这反过来又影响了他们的投机代币价值。狗狗币是最知名的模因币,但最新的模因币热潮围绕着一种名为 PEPE 的代币。该代币的灵感来自“青蛙佩佩”互联网模因,于 2023 年 250 月中旬推出,甚至在短短四天内将某人的 1 美元变成了超过 <> 万美元(尽管流动性限制阻止了投资者兑现利润)。让我们更仔细地研究一下这枚PEPE硬币。
我们将使用由@Mrftio创建的Flipsidecrypto上的$PEPE分析仪表板作为参考点,以查看我们的加密聊天机器人是否可以复制其分析。原始仪表板分为概述部分和交易分析部分,每个部分包含几个子类别。
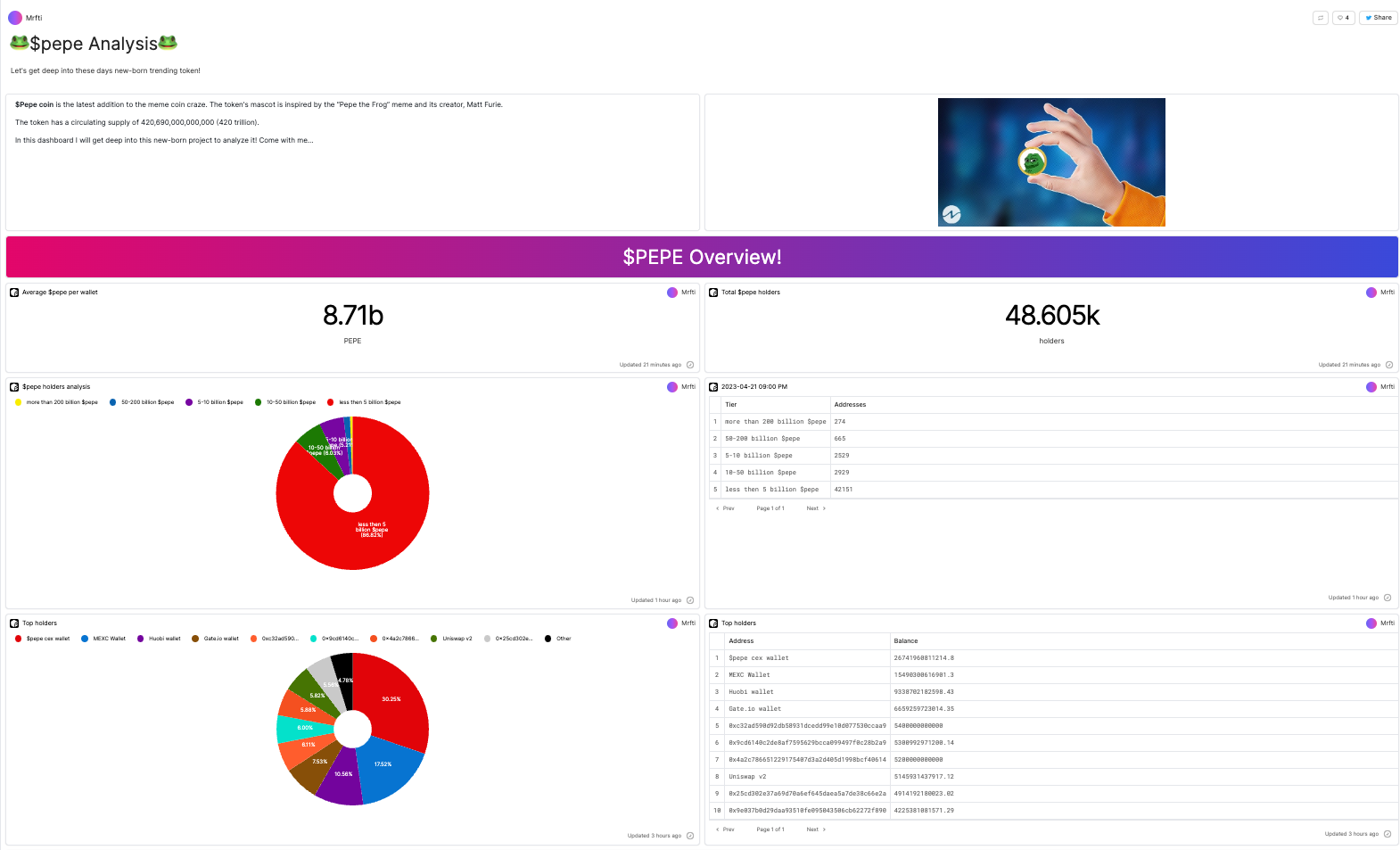
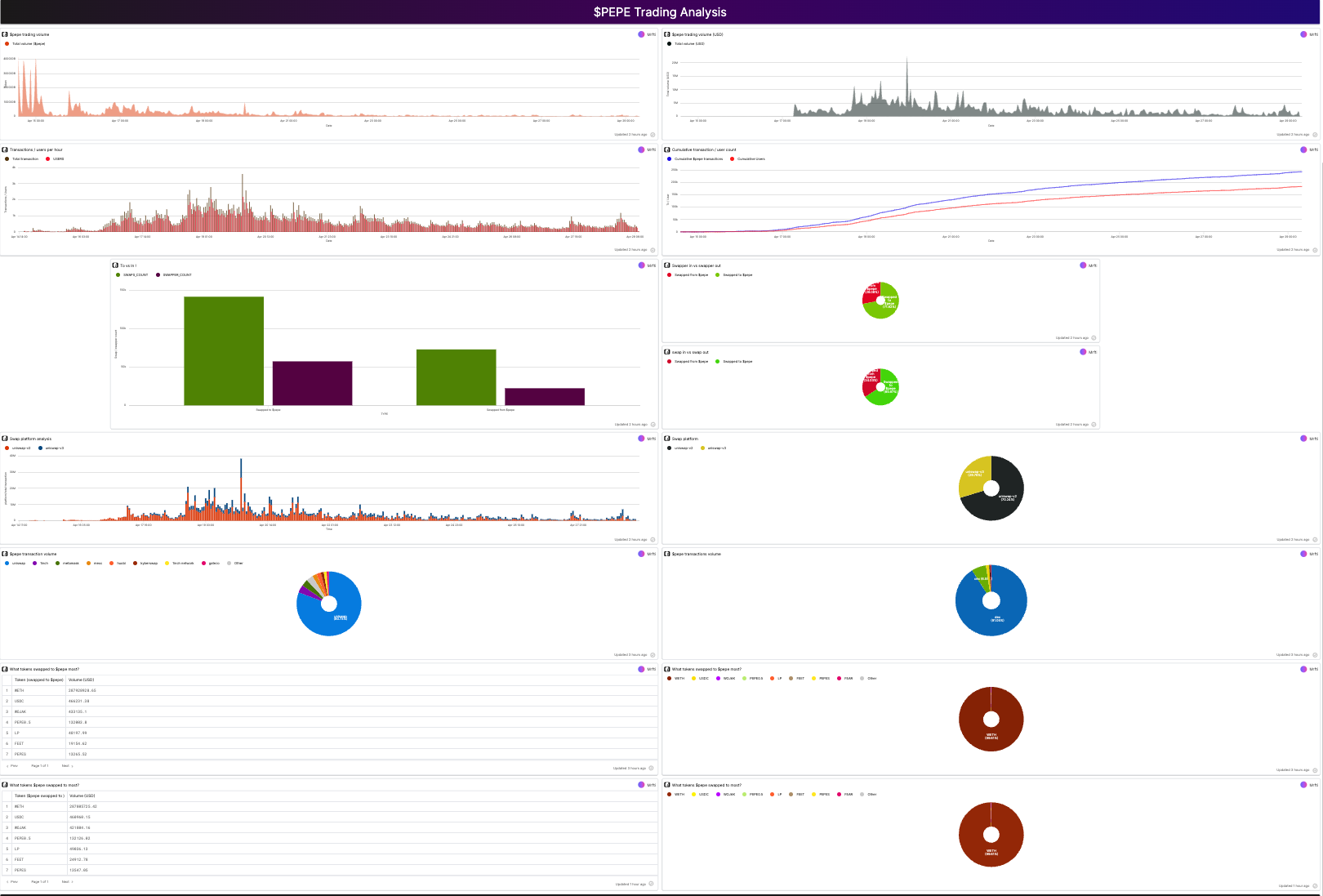
请注意,我们当前的聊天机器人不会生成可视化效果,因此我们只会评估其生成类似文本结果的能力。
代币持有者数量和每个钱包的平均代币分析
分析首先确定持有PEPE令牌的钱包地址数量和每个地址的平均令牌数量。我们向聊天机器人提出了以下问题:
提示 A:PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the number of PEPE token holders and what is the average token balance per holder?
向聊天机器人提供令牌的实际地址至关重要,因为地址到令牌符号的映射不是唯一的,合法用户和诈骗者都可以使用相同的符号创建令牌。事实上,我们在 GPT 指令提示中添加了以下内容以使其感知。
在构造包含令牌或 NFT 的查询时,如果您同时拥有其地址和符号,则必须始终更喜欢使用令牌地址而不是令牌符号,因为令牌符号通常不是唯一的。
我们还需要根据数据库的要求使用地址的小写版本。这些注意事项同样适用于直接构造其 SQL 查询的用户。
聊天机器人的回应如下:

但这是正确的吗?让我们看一下它产生的 SQL 查询:
SELECT COUNT(DISTINCT to_address) AS num_holders,
SUM(amount)/COUNT(DISTINCT to_address) AS avg_balance
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
AND has_decimal = 'true'
AND has_price = 'true'
AND amount IS NOT NULL
AND amount_usd IS NOT NULLGPT 选择该表来计算收到代币的人数,将他们视为持有者。这种方法与原始仪表板不同,原始仪表板使用表格来计算实际持有当前代币余额的人。这种差异表明 GPT 对我们问题的解释可能会有所不同。然而,有人可能会争辩说,聊天机器人的反应仍然有意义,因为它可以识别曾经处理过代币的持有者,无论他们是否仍然持有它。ez_token_transfersez_current_balances
为了获得参考仪表板预期的信息,我们修改了问题:
提示 B:PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', how many users hold current balance on this token and what is the average balance that one user owns?
这次聊天机器人的反应有所不同:

经过检查,我们发现聊天机器人正确切换到相应的表并生成了以下 SQL 查询:
SELECT COUNT(DISTINCT user_address) AS num_users,
AVG(current_bal) AS avg_balance
FROM ethereum.core.ez_current_balances
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
此查询提供具有当前余额和平均代币余额的准确持有者数量。值得注意的是,计算平均余额的更可靠方法是使用公式,如参考仪表板所示。但是,在这种情况下,表包含所有不同的 ,因此直接使用是可以接受的。SUM(current_bal)/num_usersuser_addressesAVG(current_bal)
还有其他方法来表达问题,可能会产生相同的结果。例如,我们测试的另一个有效的提示是:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the number of holders who still have a current balance and what is the average amount of that balance?
必须记住,聊天机器人的响应不是确定性的。正如我们所观察到的,即使对于产生正确结果的提示,它们也可能在其他情况下生成不同的(不正确)结果。这种不确定性进一步强调了检查和验证生成输出的实际 SQL 语句的重要性。
代币持有者组分析
下一个仪表板项目根据持有金额将 PEPE 持有人分组到五个箱中。我们构造了以下提示来重现它:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', among all users who hold current PEPE balances, can you group them according to their balance amount as follows: more than 200 billion, between 50-200 billion, between 10-50 billion PEPE, between 5-10 billion, and less than 5 billion PEPE, to find out what is the number of users in each group?
结果如下:

聊天机器人能够通过SQL语句选择正确的表并检索正确的结果,如下所示:
顶级代币持有者分析
仪表板中的下一项显示前 10 个代币持有者,我们使用以下提示:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the top 10 holders that have the highest current balance of the token?
GPT 生成的结果如下:

使用以下 SQL 查询:
SELECT dl.address_name,
ec.current_bal
FROM ethereum.core.ez_current_balances ec
JOIN ethereum.core.dim_labels dl
ON ec.user_address = dl.address
WHERE ec.contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
ORDER BY ec.current_bal DESC
LIMIT 10
聊天机器人不仅能够从表中获取前 10 名代币持有者,而且还使用表格将地址映射到标签,以便于阅读。一个小而令人惊喜的惊喜!ez_current_balancesdim_labels
代币交易量分析
仪表板上的代币交易分析从每小时交易量开始。所以我们使用了以下提示:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the hourly trading volumes of this token?
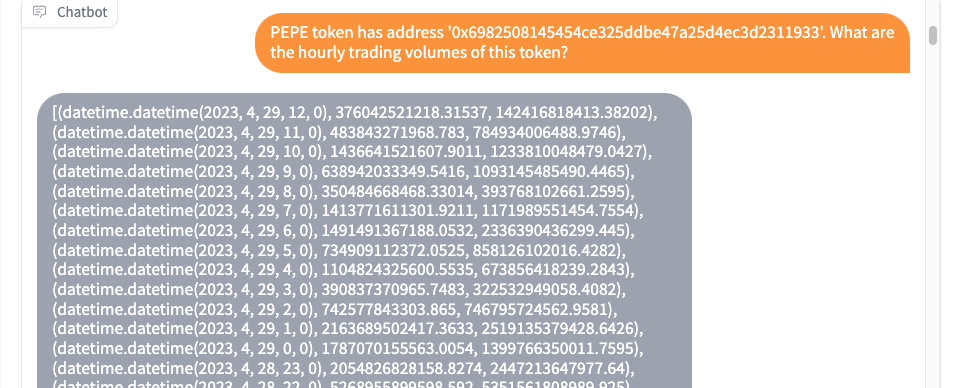
下面是它生成的 SQL 命令:
SELECT date_trunc('hour', block_timestamp) as hour,
SUM(amount_in) as hourly_volume_in,
SUM(amount_out) as hourly_volume_out
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
OR token_out = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY hour ORDER BY hour聊天机器人选择表,将时间截断为每小时,并在两者计数,并在涉及 PEPE 令牌的情况下进行计数。同样,这似乎是一个相关的答案,但不是我们最初的意图。让我们给它一个提示,以改用该表,就像在参考仪表板中一样。ez_dex_swapsamount_inamount_outtoken_intoken_outez_token_transfers

查看其下方的 SQL 查询,我们验证它现在使用与参考仪表板相同的方法:
SELECT date_trunc('hour', block_timestamp) as hour,
sum(amount) as hourly_trading_volume
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY hour ORDER BY hour DESC我们也可以要求它以美元生成金额:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the hourly trading volumes in USD of this token? (Use the ethereum.core.ez_token_transfers table)

聊天机器人使用以下 SQL 语句正确处理了它:
SELECT date_trunc('hour', block_timestamp) as hour,
sum(amount_usd) as hourly_trading_volume
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY hour ORDER BY hour DESC代币交易与用户分析
下一项是关于每个用户的令牌交易:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the average hourly trading volume per user of this token? (use the ethereum.core.ez_token_transfers table)

生成的 SQL 语句如下:
SELECT date_trunc('hour', block_timestamp) as hour,
from_address,
sum(amount) as total_volume,
count(distinct from_address) as unique_users,
sum(amount)/count(distinct from_address) as avg_volume_per_user
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY 1, 2 ORDER BY 1 DESC当尝试以美元为单位获取每个用户的交易金额时,聊天机器人忘记(或忽略)检查可用表的总体提示指令,并开始创建不存在的表。所以我们不得不在问题提示中再次强调:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the average hourly trading volume in USD per user of this token? (make sure to check available tables and use the ethereum.core.ez_token_transfers table)
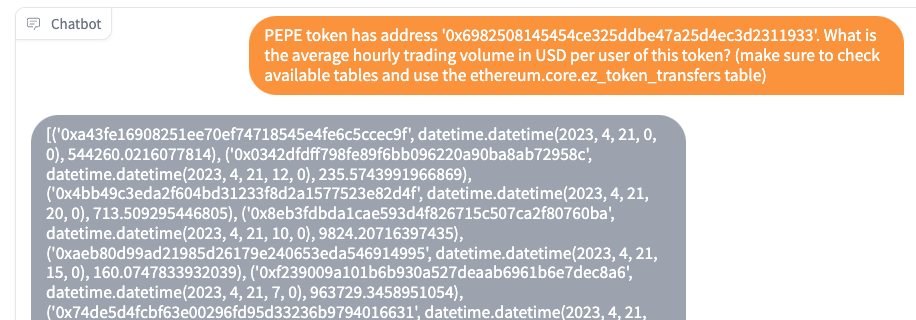
这一次,结果没有按降序排序,但整体查询逻辑仍然正确。
SELECT from_address,
date_trunc('hour', block_timestamp) as hour,
sum(amount_usd) / count(distinct from_address) as avg_hourly_trading_volume_per_user
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY 1, 2令牌“换入”和“换出”分析
仪表板还分析了令牌的交换。让我们尝试一下 ChatWeb3:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the number of swap in and swap out counts for this token and their total amount in USD?
这次 GPT 再次绕过了我们检查可用表并开始“发明”命令的指令,它甚至提到了使用 Uniswap V2 子图(提示中从未提及),以下是其思考过程的片段:
想法:我们需要找到PEPE代币的换入和换出计数及其以美元为单位的总金额。我们可以使用 Uniswap V2 子图来获取此信息。\n\n操作:\n”’\n{\n “action”: “query_snowflake_database”,\n “action_input”: {\n “query”: “选择 COUNT() 作为swap_in_count,SUM(AMOUNTUSD) 作为swap_in_amount,(从 uniswap_v2 中选择 COUNT()。交换“,其中 token0 = ‘0x6982508145454ce325ddbe47a25d4ec3d2311933’ 或 token1 = ‘0x6982508145454ce325ddbe47a25d4ec3d2311933’) – COUNT(*) 作为swap_out_count,(从 uniswap_v2 中选择总和(金额美元)。交换“,其中 token0 = ‘0x6982508145454ce325ddbe47a25d4ec3d2311933’ 或 token1 = ‘0x6982508145454ce325ddbe47a25d4ec3d2311933’) – 总和(金额美元) 作为uniswap_v2 swap_out_amount。交换“ 其中令牌0’ …
为了使 GPT 回到现实中,我们再次要求它遵循正确的工具和序列:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the number of swap in and swap out counts for this token and their total amount in USD? (please make sure to check available tables and only use the available tools)
Now it produces the following result:

Let’s check the SQL query to see whether it is valid:
SELECT COUNT(*) AS swap_in_count,
SUM(amount_in_usd) AS total_amount_in_usd,
COUNT(*) AS swap_out_count,
SUM(amount_out_usd) AS total_amount_out_usd
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
OR token_out = '0x6982508145454ce325ddbe47a25d4ec3d2311933'Well, it appears to have mixed up swap in and swap out together, which wasn’t what we wanted. To be fair, the question prompt wasn’t super clear, even if given to a human. After a few trials, we found that the following prompt produced the same result as the reference dashboard:
'PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the number of distinct swap transactions and user addresses where this token is swapped in and what is the total USD amount?

We verified the GPT-generated SQL query:
SELECT COUNT(DISTINCT tx_hash) AS num_transactions,
COUNT(DISTINCT origin_from_address) AS num_addresses,
SUM(amount_in_usd) AS total_usd_amount
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'Similarly, we were able to obtain the Swap Out side of the amount using an appropriate prompt.

GPT 生成的 SQL 查询也经过验证:
SELECT COUNT(DISTINCT tx_hash) AS num_swap_transactions,
COUNT(DISTINCT tx_to) AS num_user_addresses,
SUM(amount_out_usd) AS total_usd_amount
FROM ethereum.core.ez_dex_swaps
WHERE token_out = '0x6982508145454ce325ddbe47a25d4ec3d2311933'令牌“交换”和“交换自”分析
仪表板的最后一部分查看了与 PEPE 交换的顶级代币。让我们看看我们的 ChatWeb3 发现了什么:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', can you find out what are the top 10 tokens it has been swapped to most?

查看底层 SQL,它正在计算交换的数量:
SELECT symbol_out, COUNT(*) AS swap_count
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY symbol_out ORDER BY swap_count DESC
LIMIT 10但是参考仪表板实际上是以美元计算金额,因此我们改进了提示:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', can you find out what are the 5 tokens that it has been swapped to most in terms of amount in USD?
然而,它一无所获!

为什么?让我们看一下它生成的 SQL 语句:
SELECT token_out,
SUM(amount_out_usd) AS total_amount_usd
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY token_out ORDER BY total_amount_usd DESC
LIMIT 5
我们意识到查询似乎是正确的,并最终从表的注释中找到了一个可能的解释:ez_dex_swaps
注意:已制定规则,如果该数字在amount_in_USD和amount_out_usd之间差异太大,则取消amount_USD。在价格波动非常大的情况动性较低的代币的交换可能会发生这种情况。
鉴于这是一个高度缺乏流动性的代币,相关amount_USD字段很可能已被取消。使用的参考仪表板 ,所以让我们给 GPT 一个提示:amount_in_usd
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', can you find out the top 5 tokens that it has been swapped to measured in the USD amount of input tokens? (make sure to produce concise thoughts and generate appropriate tool inputs)
请注意,我们添加了显式提醒提示的另一部分,要求它产生简洁的想法并生成适当的工具输入。这是因为它开始变得过于健谈,并在中间步骤中产生更长的想法,由于提示窗口大小限制而导致错误。

至少这一次它产生了预期的结果,正如底层 SQL 语句所证实的那样:
SELECT symbol_out,
SUM(amount_in_usd) AS total_input_usd
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
AND amount_in_usd IS NOT NULL
GROUP BY symbol_out ORDER BY total_input_usd DESC
LIMIT 5现在让我们看看掉期的反面:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', can you find the top 5 token symbols that have been swapped into PEPE most and order them by their USD amount? (make sure to produce concise thoughts and generate appropriate tool inputs)

但它一直弄错“交换”端,并且仍在选择输出令牌。
SELECT symbol_out,
SUM(amount_out_usd) AS total_amount_usd
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY symbol_out ORDER BY total_amount_usd DESC
LIMIT 5在我们给它更明确的提示之后:check your token input vs. output selection
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', Find the 5 top token symbols that have been swapped into PEPE, and order them by the swap amount in USD? (make sure to check your token input vs. output selection)
它最终产生正确的结果:

经验证来自正确的 SQL 语句:
SELECT token_in,
SUM(amount_out_usd) AS total_usd_value
FROM ethereum.core.ez_dex_swaps
WHERE token_out = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY token_in ORDER BY total_usd_value DESC
LIMIT 5
吸取的教训、挑战和讨论
此项目期间遇到的主要挑战包括 GPT 提示大小限制、响应的非确定性以及推理和指令遵循。
提示大小约束
GPT-4.3-turbo 模型的 5K 提示大小窗口存在一些限制,会影响查询过程中的表选择和迭代次数。
表索引缩放和优化
提示大小限制了我们可以向 GPT 呈现的表的数量及其各自的信息。扩展它的几个潜在解决方案是:
- 水平扩展:将表信息内容拆分为多个部分,并通过单独的查询提交。
- 垂直缩放:使用较新的 GPT 型号,例如 GPT-4,这些型号提供更大的提示窗口(8K 和 32K),但成本更高。
- 卸载:将表元数据存储在向量存储索引中,并使用语义搜索进行表选择。
元数据优化还可以增强 GPT 在决策中的相关性。目前,我们使用现有的表注释和示例行值,但可以扩展元数据范围。例如,包含更多数据库模型详细信息可以帮助 GPT 了解表和视图的结构和关系。
迭代步骤
提示大小限制会影响查询过程中可以运行的迭代次数。在当前的实现中,所有中间步骤的观察结果都累积到提示符中,导致它很快填满。该系统需要改进以解决这些问题,通过创建更多原子和模块化步骤来解决这些问题,这些步骤对提示大小友好,同时保持思维过程的连续性。
GPT 响应的非确定性
GPT 的非确定性意味着它可能会在不同的运行中产生不同的结果,即使有“良好”提示也是如此。这需要验证底层 SQL 语句,这抵消了“不需要 SQL 技能”的好处。观察到的一些相关问题包括:
GPT 输出的最大长度:
出乎意料的是,GPT 模型的参数设置可能会导致问题。此参数指定模型应生成的最大语言标记数,它是提示窗口的一部分。我们将其设置为(总 4K 提示大小),因为我们希望为数据库表信息等输入留出足够的空间。我们还尝试放宽限制,看看会发生什么。如果我们将其设置为甚至无限,GPT 的想法就会变得过于健谈。但问题是,越长的想法伴随着简单问题的复杂解决方案。例如,它将为从未存在的表和列创建许多连接语句。从某种意义上说,给它更多的思考空间会让表演“更糟”!即使有我们明确的最大代币限制,它有时仍然会超过限制。这会导致错误,因为程序将仅强制返回生成的前 256 个语言标记,而程序的其余部分无法解析该不完整的响应。在这些情况下,在问题提示中明确提醒 GPT,例如“确保产生简洁的想法”通常可以缓解问题。max_tokens2561K256
推理和指导遵循
GPT 表现出强大的推理能力,但不时会产生有缺陷的结果。它的非确定性可能导致它有时更好地遵循指令(例如,检查可用表,在构造查询之前获取表元数据),而在其他方面则更糟。问题提示中的简单提醒通常可以使其恢复正常状态。众所周知,较新的型号(如 GPT-4)会更严格地遵循系统类别说明,这有望缓解此问题。
机会、下一步和未来工作
尽管当前系统存在局限性,但仍有许多方法可以增强其功能并使其对区块链数据分析更有用。
对话记忆和副驾驶模式
在目前的状态下,GPT 可能更适合作为用户的共同驾驶或助手,这些用户至少可以在探索大型数据库时验证 SQL 语句。通过启用会话记忆,用户可以保持更长的对话,并在发现新信息时提供更多指导。这种方法还在一定程度上解决了提示大小限制问题,使 ChatWeb3 具有更深入的用例。
表索引扩展和多链功能
ChatWeb3 被设计为多链就绪,能够合并来自不同数据库的表,代表各种链。通过将前面提到的扩展解决方案应用于表索引,系统可以立即适应跨链分析。
利用自动 GPT/婴儿 AGI
探索使用Auto-GPT和Baby-AGI进行分析任务是另一个令人兴奋的前景。GPT 可以指定目标,并允许 GPT 决定哪些表、列和信息对生成有见地的分析有用,而不是专注于验证性任务。这种方法利用了 GPT 的生成优势。
替代办法
目前使用 GPT 的文本到 SQL 功能进行基于聊天的区块链数据库查询的方法并不是集成 AI 和区块链数据分析的唯一方法。其他一些可能性包括:
- 为区块链领域定制模型:微调现有模型或专门为区块链数据训练新模型可能会带来更有效的解决方案。
- 探索不同的数据格式:与其将模型限制为处理SQL数据库格式信息,不如使用原始区块链记录对其进行训练,从而产生替代解决方案。
- 将 ChatGPT 与其他 API 集成:将 ChatGPT 与旨在促进区块链数据分析的各种 API 连接起来,可以扩展其功能并实现更全面的见解。
结论
利用ChatGPT的文本到SQL功能使所有人都可以访问区块链数据分析是一个雄心勃勃的愿景。在本文中,我们介绍了ChatWeb3,这是一个使用ChatGPT,Langchain和Flipsidecrypto构建的原型,它使用户能够与区块链数据库“聊天”。我们的初步实验揭示了许多挑战,这些挑战源于GPT响应的非确定性以及提示窗口约束等因素,这表明当前的系统还没有完全准备好完全自主的体验。然而,它为区块链数据分析提供了一个更容易获得的未来。
通过会话记忆、表索引缩放和优化、自动 GPT/baby-AGI 功能以及替代 AI 方法增强系统,我们可以更接近于为更广泛的受众实现区块链数据分析的民主化。随着人工智能的不断发展,将ChatGPT和类似的大型语言模型集成到区块链数据分析工具中可能会变得更加无缝,从而为大众释放这些技术的全部潜力。
这个原型的代码是开源的,可以在 https://github.com/inWeb3ai/chatWeb3 获得。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
